
Veeva Integrations by IntuitionLabs
IntuitionLabs specializes in integrating Vault applications and Vault CRM (as well as legacy Veeva CRM on Salesforce) with your most important business systems. We deliver secure, scalable, and compliant integrations for pharma and life sciences organizations, leveraging current Veeva Connections, AI Agents, and X-Pages where appropriate.
Accelerate Your Digital Transformation
Connect Vault applications and Vault CRM to your data warehouse, EHR, and ERP systems. Unlock real-time analytics, automate compliance, and drive business value.

What We Can Integrate
- Vault CRM & legacy Veeva CRM (Salesforce): Two-way sync for accounts, contacts, activities, and CLM/Approved Email content.
- Data Warehouses (Snowflake, AWS, Azure): Automated data feeds from Vault applications for analytics, dashboards, and AI/ML.
- EHR & Clinical Systems (Epic, Cerner): HL7/FHIR adapters and custom connectors to surface patient or trial data in Vault workflows.
- Master Data Management (Veeva Network): Bi-directional HCP/HCO data integration for unified customer records.
- Content Management (Box, Alfresco): Document lifecycle sync and regulatory content staging.
- ERP & Finance (SAP, Oracle): Integration for batch release, quality, and compliance workflows.
Automated Data Sync
CRM & Commercial Integration
Clinical Data Ingestion
Content & Document Management
Integration Accelerators & Reusable Modules
We are developing a suite of accelerators and reusable modules to help clients integrate Veeva faster and more reliably. Let us know which would be most valuable for your team.
Vault to Snowflake Connector
Vault CRM / Veeva CRM Sync Toolkit
HL7/FHIR Clinical Data Adapter
Document Lifecycle Automation Scripts
Validation & Compliance Toolkit
Integration Monitoring Dashboard
Our Integration Technology Partners

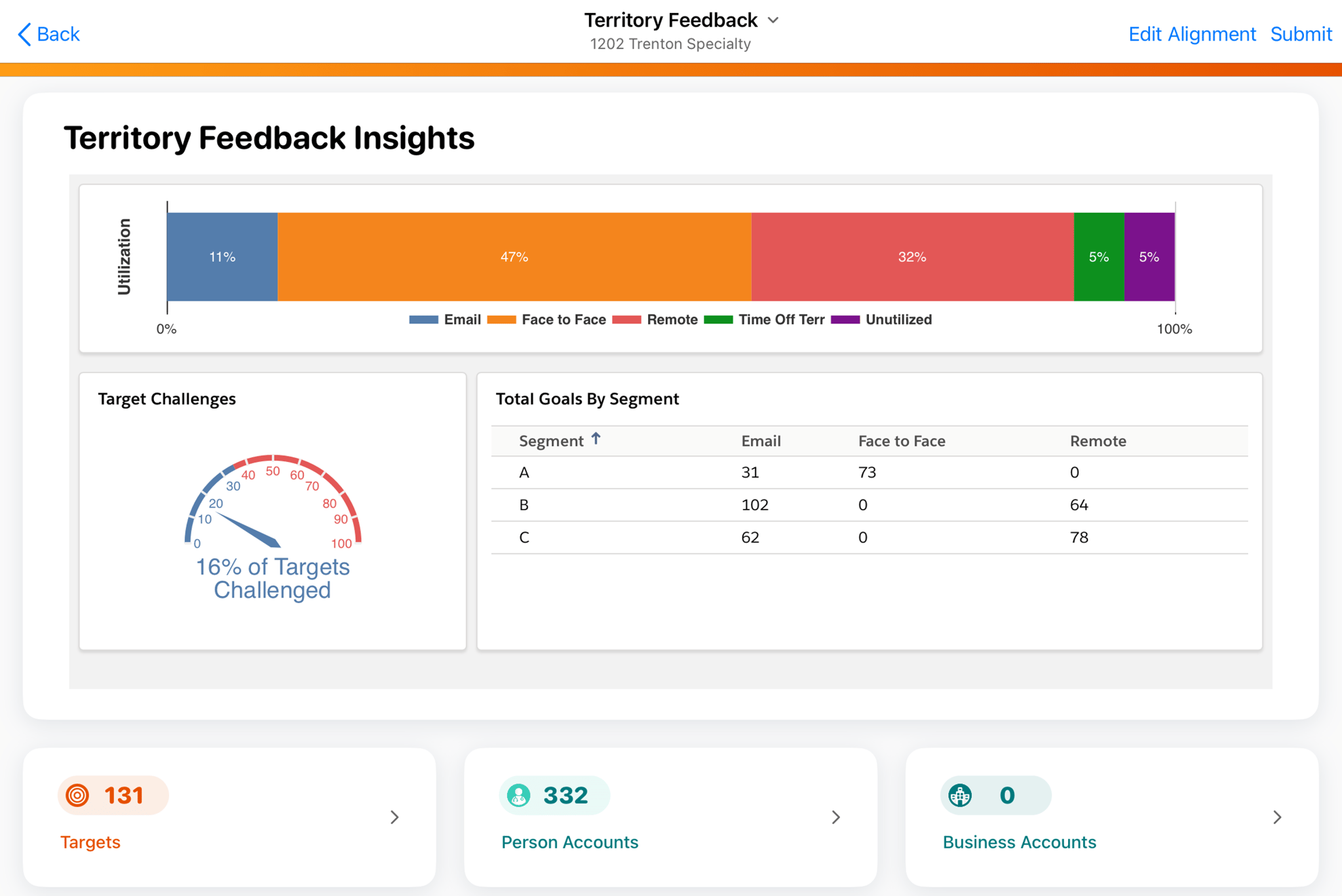


Example: Vault to Data Warehouse
We helped a global pharma client automate daily data sync from Vault applications to Snowflake, enabling real-time analytics and AI-driven insights across R&D and commercial teams.
- Automated Extracts: Direct Data API delivers full and incremental data to Snowflake.
- Compliance: All transfers encrypted, with audit trails and field-level masking.
- Business Impact: Faster reporting, improved data quality, and better decision-making.
Ready to Integrate Veeva?
Contact IntuitionLabs to accelerate your Veeva integration project and unlock new business value.
Get Started